R语言实现LDA主题模型分析知乎话题
这是一篇关于文本主题分析的应用实践,主要尝试聚焦几个问题,什么是LDA主题模型?如何使用LDA主题模型进行文本?我们将知乎上面的转基因话题精华帖下面的提问分成六大主题进行实践。
转基因“风云再起”

2017年5月18日璞谷塘悄然开张,这是小崔线上贩卖非转基因食品的网店,所卖的商品价格平均高于市场价5倍,小崔打着反转基因的名号卖着反转基因的食品,不由得令人想起了那些年小崔引发的转基因争议——

▲2015-3-25 崔永元和卢大儒教授的激烈争辩

转基因在国内外研究来说不是一个新话题,以中国为例,我们可以从新浪微指数的时序图里面发现,转基因问题一直是大家广泛讨论的话题,而转基因面临的争论主要和名人“崔永元”相关。
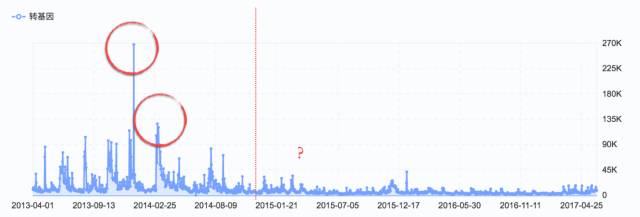
由于新浪微指数的时间限制,只能搜索在2014年之后的关键词数据,其中我们可以发现,在2015年之前,大家在微博上讨论转基因还是相当频繁:
在2013年底出现了一个最高峰。此次引发了网民的广泛关注和讨论的微博热点是崔永元和方舟子之间关于转基因的争辩的升级,小崔和小方“互相问候了家人”;
在2014年3月左右的一个小高潮就是崔永元的报告性影片《小崔考察转基因》的推出;
但是2015后我们可以发现,微博上的讨论不如之前那样剧烈,就连稍近一些的热点:崔永元“大战”卢大儒教授这一事件,似乎也没有引发像之前那样的广泛微博关注。
在2013年底出现了一个最高峰。此次引发了网民的广泛关注和讨论的微博热点是崔永元和方舟子之间关于转基因的争辩的升级,小崔和小方“互相问候了家人”;
在2014年3月左右的一个小高潮就是崔永元的报告性影片《小崔考察转基因》的推出;
但是2015后我们可以发现,微博上的讨论不如之前那样剧烈,就连稍近一些的热点:崔永元“大战”卢大儒教授这一事件,似乎也没有引发像之前那样的广泛微博关注。
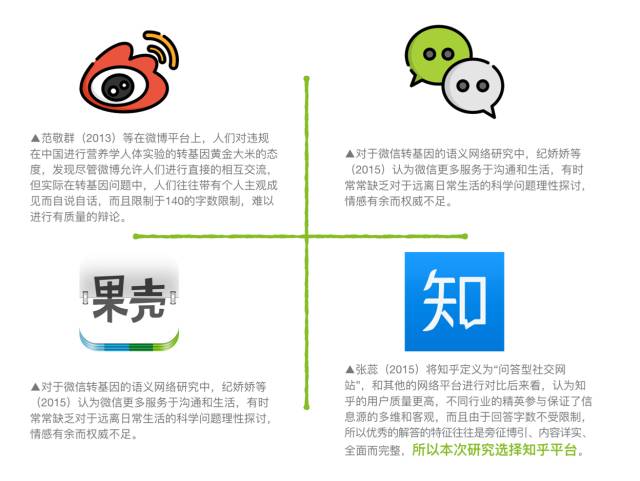
网络上关于转基因的讨论,似乎主战场已经从新浪微博进行了转移。
网民关于转基因的讨论迁移去了哪里?
比较几个主流的新媒体平台,可以发现:

LDA主题模型进行文本分析
LDA主题模型,即Latent Dirichlet Allocation,是自然语言处理(NLP)中对于隐藏主题进行挖掘分析的重要模型之一。之所以称之为“隐藏”,是因为主题在这个模型中不必求出的变量,隐藏在“主题-词语概率分布”和“文档-主题概率分布”里,使用狄利克雷分布求解最终概率分布,确定潜在的主题,该模型由Blei提出。

▼如果我们用矩阵的乘法可以比较简单地了解这个模型的初步机制,

可以认为,LDA主题模型在某种程度上模拟人脑对于语料的主题分类,内容分析过程中研究员所进行的类目建构过程,模型假定每篇文章中作者选择的词语都是通过以下这一过程:“以某种概率选择了某个主题,并从这个主题中以一定概率选择某个词语”。所以我们对于语料进行LDA建模,就是从语料库中挖掘出不同主题并进行分析,换言之,LDA提供了一种较为方便地量化研究主题的机器学习方法。
付诸实践
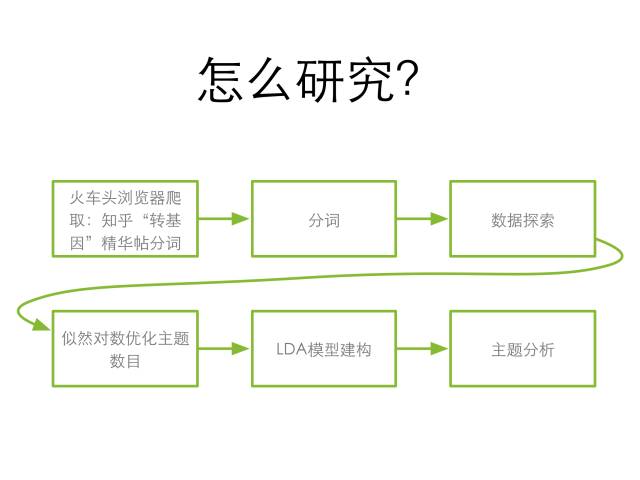
1. 火车头爬取知乎“转基因”话题精华帖前10页
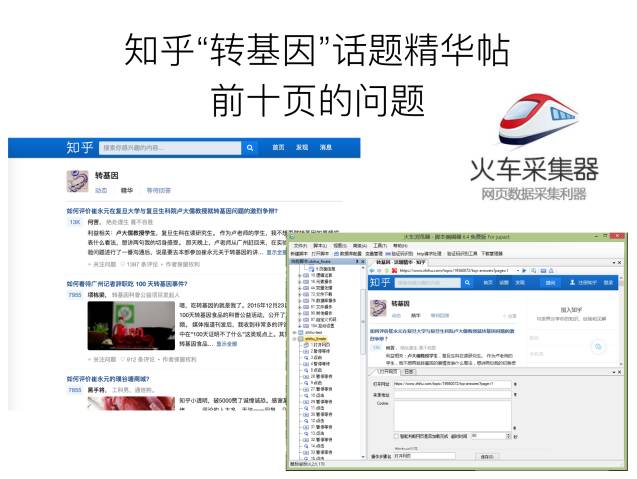

▲爬取时间为2017年5月15日。本次研究共抓取197条知乎问题及问题创建的时间,问题共计4,655字,回答共计248,292个字。
2.分词

▲用R对知乎问题进行切分,使用jiebaR对采集到的文本数据进行初步分词,生成初步分词文本。
由于本次分词内容是较为专业化的生物领域,默认分词系统词典覆盖范围不够,导致初步分词结果不甚理想,笔者发现分词结果中出现不少错误,比如无法正确分出相关词汇:
“转基因”被分成了“转基”、“因”;
“卢大儒”容易被识别成“卢”、“大儒”;
“马兜铃内酰胺”被分成“马”、“兜铃”、“内酰胺”等
“转基因”被分成了“转基”、“因”;
“卢大儒”容易被识别成“卢”、“大儒”;
“马兜铃内酰胺”被分成“马”、“兜铃”、“内酰胺”等
所以笔者对jiebaR中用户分词词典(user.dict.utf8)添加了搜狗细胞词库中生物词典以及搜狗词典,使分词文本里的有些固定词语得以识别,同时也增加中文停用词表(stop_word.utf8),能够对虚词(比如“的”、“了”、“吧”等)、助词(比如“啊”、“呀”、“罢”等)、无义常用词和标点符号进行过滤。搜狗细胞词库下载的词典格式为.scel,但是导入R中的词典的格式需要为utf-8编码的txt,所以使用R中的cidian包,对词典格式进行转化导入。
3.数据探索

▲对list中的分词用R中以Tf-Idf权重统计,我们再以wordcloud2包进行的可视化词云展现,通过Tf-Idf权重统计,从词云中,我们可以发现知乎上面对于转基因问题的讨论比较多且具有一定区分度的词语为“食品”、“崔永元”、“知乎”、“支持”或“反对”等,当然也存在“是否”这样的词语需要进行去除。
之后,使用tm包对分词文本处理,对jieba分词之后的list创建语料库(corpus),并创建文档-单词矩阵(DTM),在创建矩阵的过程中的约束条件(control)为该分词出现的最小频率(minDocFreq)是2,出现频率过低没有录入的必要,分词的长度(wordLengths)是2个字符以上(因为现代汉语中一般单字不太会有含义,所以此处删去了长度为1个字符的分词),每个矩阵中的元素是以词频(Tf)作为分词的权重,这也是对文本特征选择的过程。
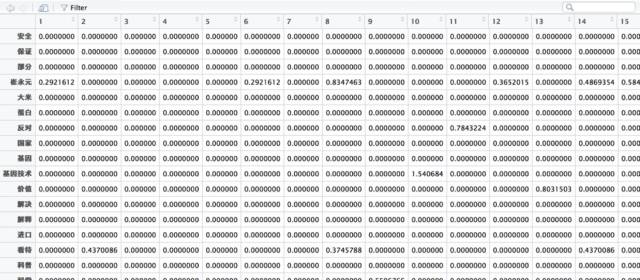
▲稀松矩阵的行变量为文档的编号,矩阵的列变量为语料库中的分词。
4.似然对数优化主题数目
LDA主题模型是无监督机器学习,使用最大似然估计进行最优化主题个数的选取。
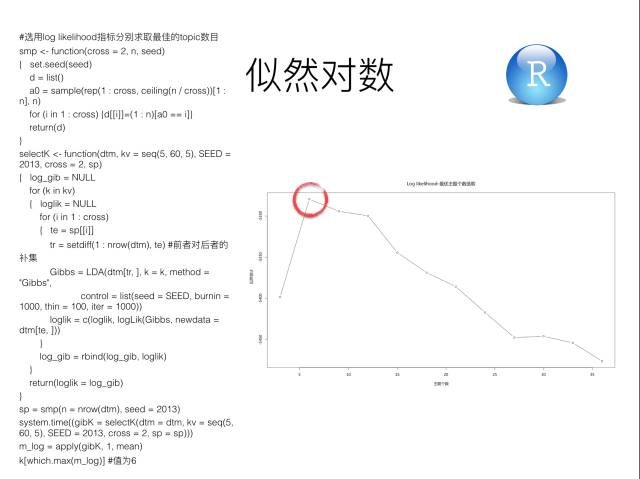
▲从似然估计的结果可以看出,当主题个数定为6的时候,似然估计数最大,即知乎问题分为6个主题的可能性比较大,所以LDA模型中的主题个数参数定为k = 6。
5.LDA主题模型建构
最后,使用topicmodels对已经分词好的DTM进行LDA主题建模

▲将模型生成的六个主题中的前五个高频词取出,进行主题分析,我们可以发现最终我们得到了六个主题。
6.主题分析
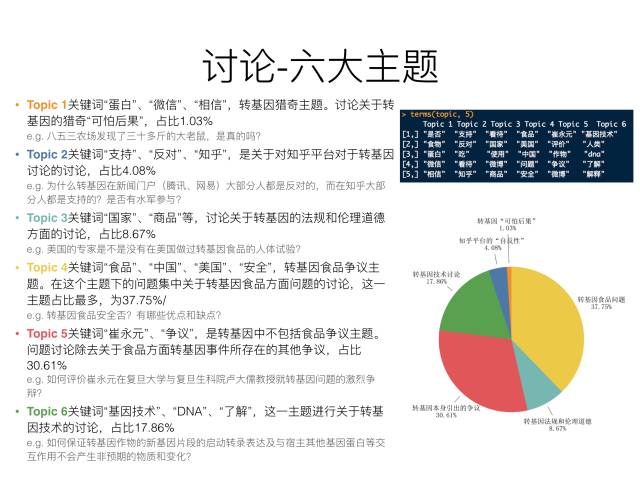
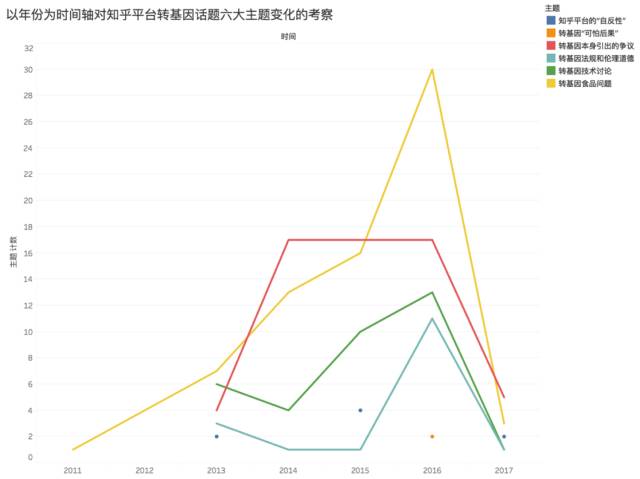
▼将主题以年作为时间维度进行统计,再用Tableau进行可视化,限于篇幅不在此展开
最后……

▲知乎也已经在做这方面的尝试,比如说“知乎索引”,就是对一个话题下面的问题进行主题分类,但更多地,知乎雇佣人力去进行索引的编纂,而LDA主题模型可以在一定程度上分摊部分人工的工作,尤其是前期大量数据混杂的情况下,对于文本的主题的初分。
返回搜狐,查看更多
责任编辑: